
Try Paper Lantern: code.paperlantern.ai - join 100+ engineers and researchers already using it.
Paper Lantern is an MCP server that gives AI agents access to 2 million+ computer science research papers. For each query, it reasons over hundreds of papers, finds multiple candidates for your problem, evaluates their limitations and applicability to your specific setting, and returns implementation-ready guidance – hyperparameters, failure modes, what to watch out for.
We connected Paper Lantern to an autoresearch agent (Andrej Karpathy's framework for autonomous ML research) and ran it head-to-head against the same agent without it. A coding agent comes up with an idea to make the model learn better, tries it for 5 minutes, keeps or discards it based on results, then moves on to the next idea. 100 ideas, overnight. Same GPU, same code, same starting model. The only difference: where the ideas came from. One agent relied on its training data and web search. The other had Paper Lantern feeding it research-backed ideas from 2 million papers.
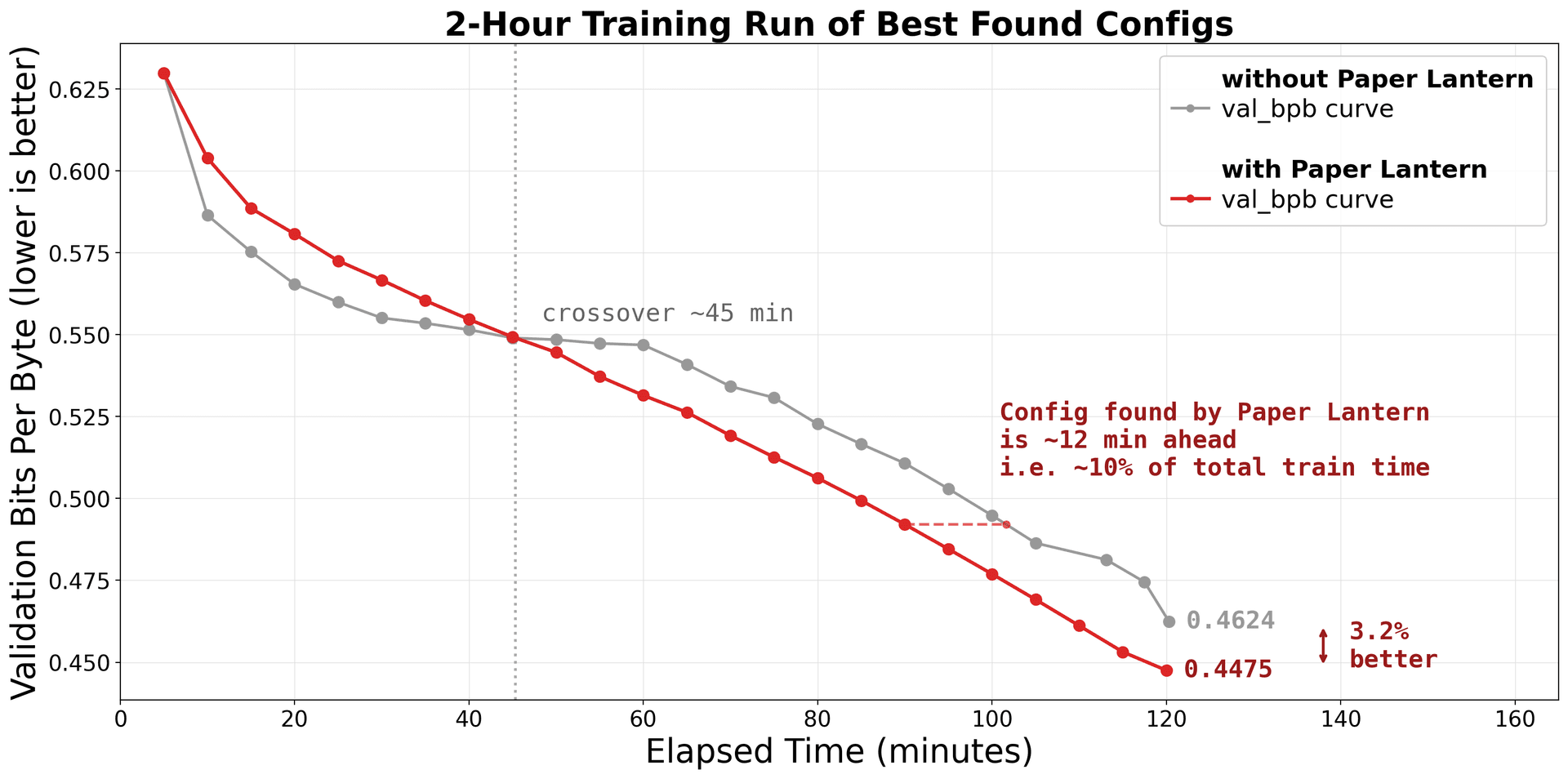
When we trained the best configuration from each run for 2 hours, the Paper Lantern configuration reached 3.2% lower validation loss – and the gap was still widening. In language modeling, gains compound: a 3.2% reduction in validation loss translates to the model is measurably better at predicting every next token, across every sentence. And because the gap was widening at the 2-hour mark, longer training would amplify the difference further.
And this was on a ~7M parameter model with an already highly-optimized baseline – one of the most well-explored settings in ML, with the least room for improvement. At larger scales, where the optimization landscape is wider and less explored, the opportunity for Paper Lantern is even bigger.
During the autoresearch run itself, Paper Lantern considered 520 papers, cited 100 unique papers in its analysis, and the agent directly tried ideas from 25 of them. 10 of those papers were published in 2025 or later.
The Setup
Two identical autoresearch runs, 100 experiments each. Only difference: one had Paper Lantern connected as an MCP tool. See Appendix B: Experiment Details for the full configuration.
Comparison 1: The Autoresearch Run
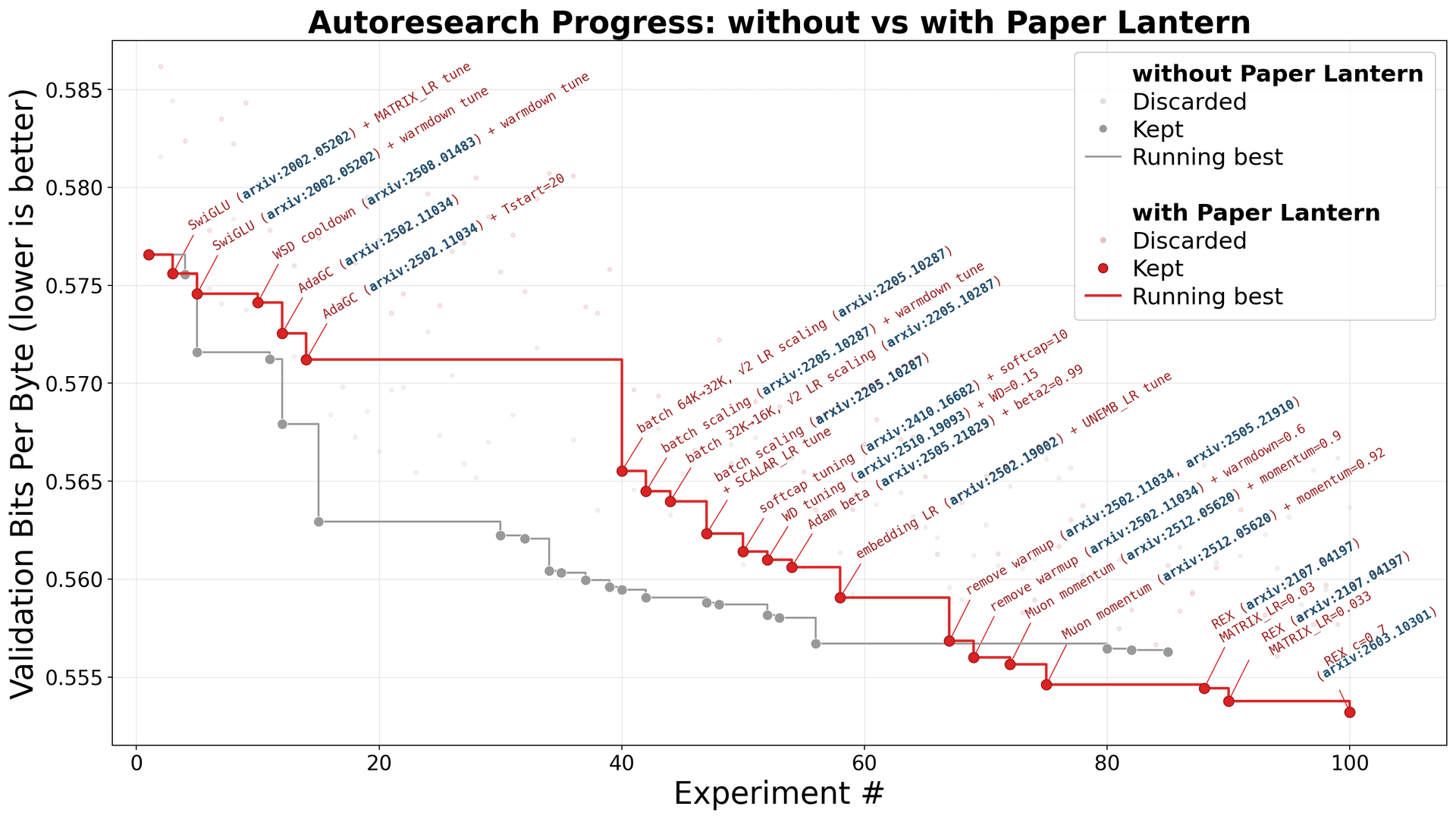
Without Paper Lantern – training data + web search
The agent explored the standard ML playbook: SwiGLU activations, batch size tuning, learning rate schedules, gradient clipping, weight decay adjustments, MLP expansion. No paper citations – all from training data. Its biggest win came from halving the batch size – more optimizer steps per 5-minute window.
Result: 3.67% improvement over baseline (val_bpb 0.577 → 0.556). Solid – but even with web search, the agent landed only on well-known techniques. The agent with Paper Lantern started from the research frontier.
With Paper Lantern – training data + web search + 2M research papers
Before each new idea, the agent queried Paper Lantern. Over the course of the run, Paper Lantern considered 520 papers, cited 100 unique papers in its synthesis, and the agent directly tried ideas from 25 of them. For each idea, it compared multiple candidates, evaluated their limitations and fit for this specific architecture, and returned implementation-ready guidance. The techniques it surfaced were qualitatively different from the standard playbook.
Result: 4.05% improvement over baseline (val_bpb 0.577 → 0.553).
See Appendix A: Full Technique Comparison for the complete table with all 14 paper citations.
Here are two examples of what that looked like in practice.
Example 1: Batch scaling – same intuition, different knowledge, different outcome.
Both agents tried halving the batch size. The agent without Paper Lantern failed – it didn't know how to adjust the learning rate to compensate. The agent with Paper Lantern asked:
Same intuition. Different knowledge. Different outcome.
Example 2: AdaGC – a technique invisible without research access.
The agent needed to stabilize gradient norms in early training. This isn't a problem Claude Code would know a recent solution to – AdaGC was published in February 2025.
Every improvement traces back to a specific paper that Paper Lantern surfaced – 10 of the 15 papers it cited were published in 2025 or later. Not every paper idea worked – DyT (arxiv:2503.10622) and SeeDNorm (arxiv:2510.22777) turned out to be incompatible with this model's architecture. That's expected – research gives you better options, not guaranteed wins.
Comparison 2: Training the Best Config for 2 Hours
The 5-minute experiments tell one story. But which configuration is actually better when given real compute?
We took the best configuration from each run and trained for 2 hours on the same machine. Same data, same evaluation, same hardware.
The Paper Lantern configuration reached 0.4475 – 3.2% better.
Why 3.2% matters
In language modeling, validation loss improvements are hard-won and compounding. A few points of context:
- The gap was still widening. At the 1-hour mark, the loss difference was 2.1%. By 90 minutes, 2.7%. By 2 hours, 3.2%. This isn't a one-time trick – it's a fundamentally better configuration that compounds with more compute. Given a longer training run, the gap would keep growing.
- It came from architecture and optimization choices, not hyperparameter luck. The without-PL agent found good hyperparameters for a standard architecture. The with-PL agent found a different architecture – one informed by recent papers on gradient clipping, learning rate scheduling, and batch scaling. These are structural improvements that scale, not lucky parameter rolls that plateau.
- For reference: Individual training improvements like AdamW, cosine LR schedules, or Sophia each typically improve validation loss by 1-3% – and each took months of dedicated research. Paper Lantern helped an autonomous agent stack multiple such gains in a single run.
What Surprised Us
We expected the agent with Paper Lantern to find more techniques – that's the obvious win. What we didn't expect was how much the quality of exploration changed. The without-PL agent had good instincts – it tried batch size reduction, it tried different schedules – but it was guessing at implementation details. The with-PL agent was making informed decisions: the right scaling rule, the right hyperparameters, the right order of operations. Same ideas, but one agent had the map and the other was navigating by feel.
The other surprise was how the gap compounds. A 0.4% difference after 5 minutes becomes a 3.2% difference after 2 hours. Research access doesn't just help you find one better trick – it helps you find a fundamentally better configuration, and that advantage grows with every additional minute of compute.
The gains at larger scales – bigger models, more data, longer training, where the optimization landscape is wider and less explored – are bigger.
Try Paper Lantern
This study used ML training as a testbed, but Paper Lantern covers the full breadth of computer science research – from system design and databases to algorithms, infrastructure, and security. Whatever technical problem your agent is working on, there's research it hasn't seen.
Paper Lantern works with any MCP client – coding agents like Claude Code, Cursor, Windsurf, GitHub Copilot, and Cline, or AI chats like Claude.ai and ChatGPT.
Get started at code.paperlantern.ai - join 100+ engineers and researchers already using it.
Appendix A: Full Technique Comparison
A.1 With Paper Lantern – every improvement traced to a paper
A.2 Without Paper Lantern – standard ML playbook
A.3 Paper Lantern found 15+ papers across this run
Each idea started with Paper Lantern's explore_approaches tool, which returned multiple candidate techniques from recent papers. The agent then used deep_dive to get implementation details on the most promising one. In some cases, compare_approaches was used to evaluate multiple candidates side by side before committing.
The full list of papers PL cited during this study:
Appendix B: Experiment Details
- Baseline model: ~7M parameter GPT trained on TinyStories
- Hardware: M4 Pro, 48GB
- Agent: Claude Code, out of the box
- Rules: 5-minute training budget per experiment, max 3 hyperparameter-tuning attempts per idea
- Fork: autoresearch-macos, optimized for Apple Silicon
- Both runs: 100 experiments each, identical starting conditions